
Publications
Featured Publications
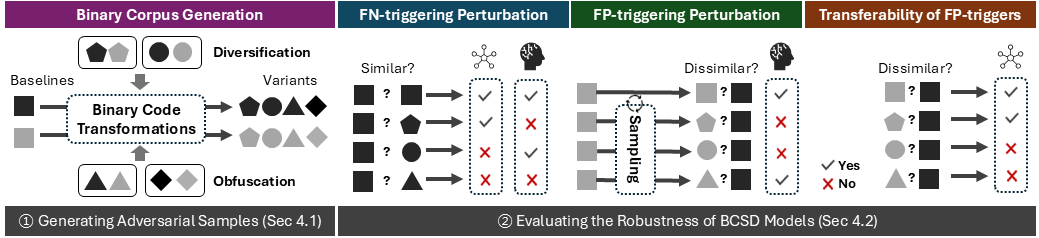
Fool Me If You Can: On the Robustness of Binary Code Similarity Detection Models against Semantics-preserving Transformations (To appear)
In ACM International Conference on Foundations of Software Engineering, 2026 (FSE '26)

UnPII: Unlearning Personally Identifiable Information with Quantifiable Exposure Risk
In the Software Engineering in Practice track of the International Conference on Software Engineering, 2026 (ICSE-SEIP '26)
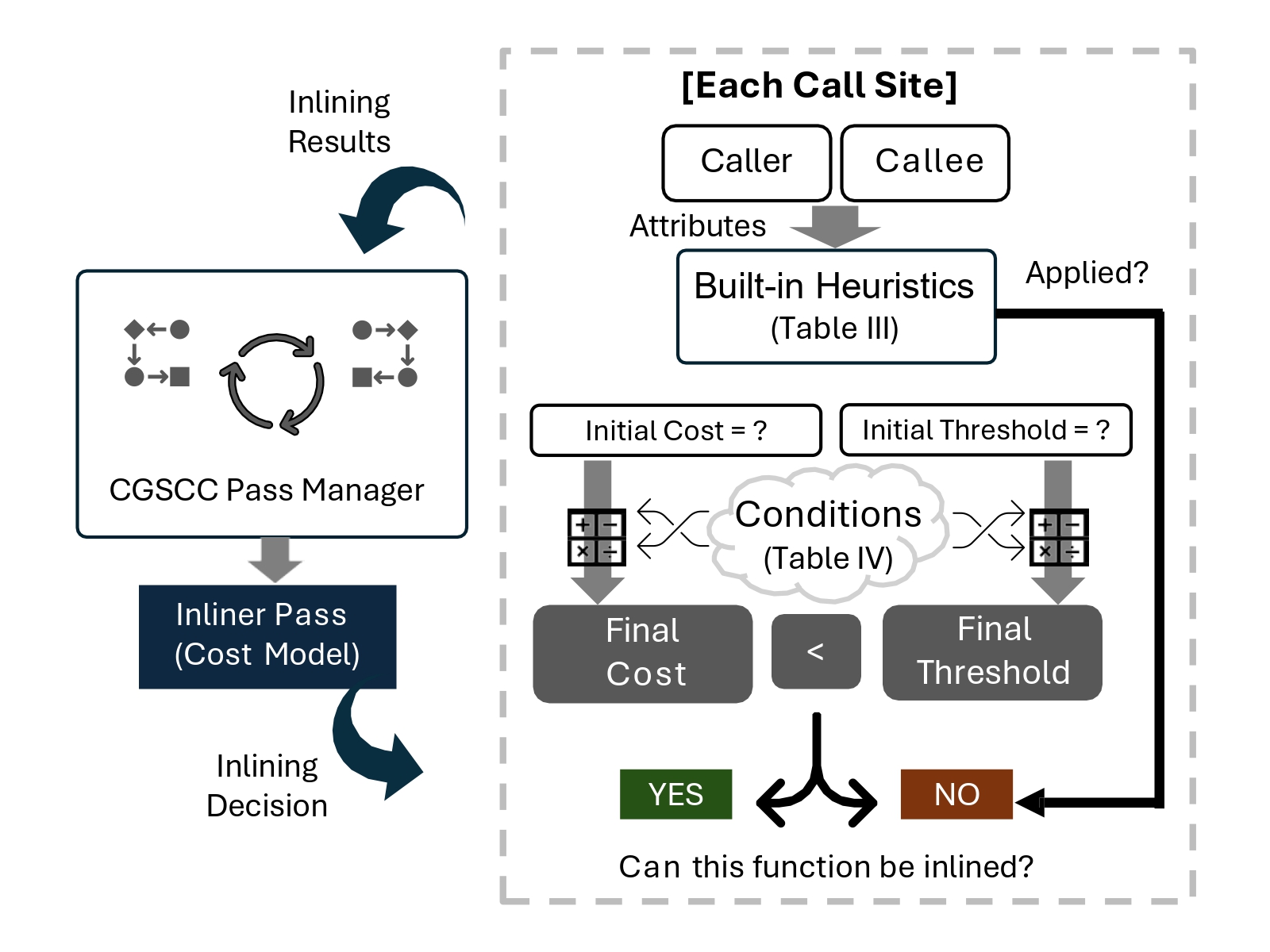
A Deep Dive into Function Inlining and its Security Implications for ML-based Binary Analysis
In Network and Distributed System Security Symposium, 2026 (NDSS ’26)
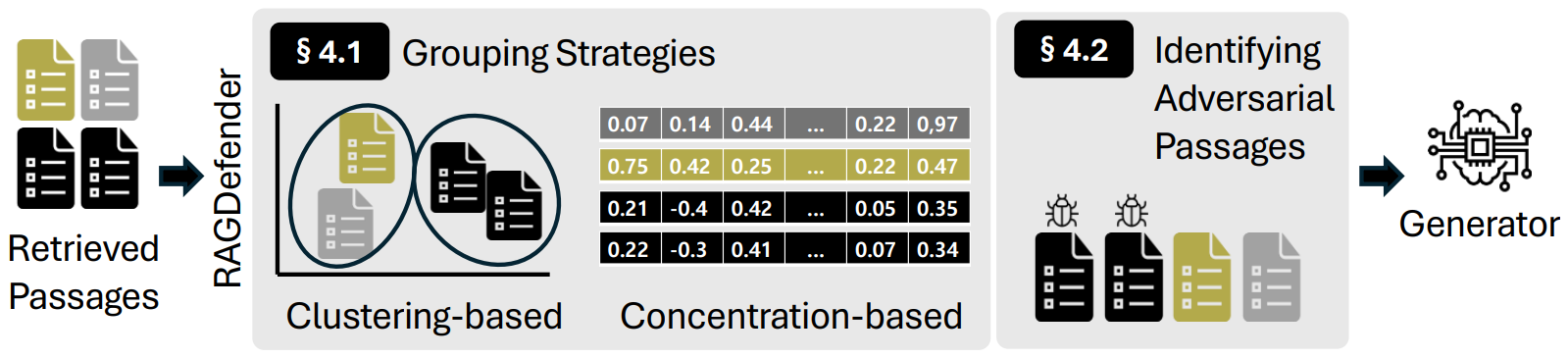
Rescuing the Unpoisoned: Efficient Defense against Knowledge Corruption Attacks on RAG Systems
In the 41th Annual Computer Security Applications Conference, 2025 (ACSAC '25)
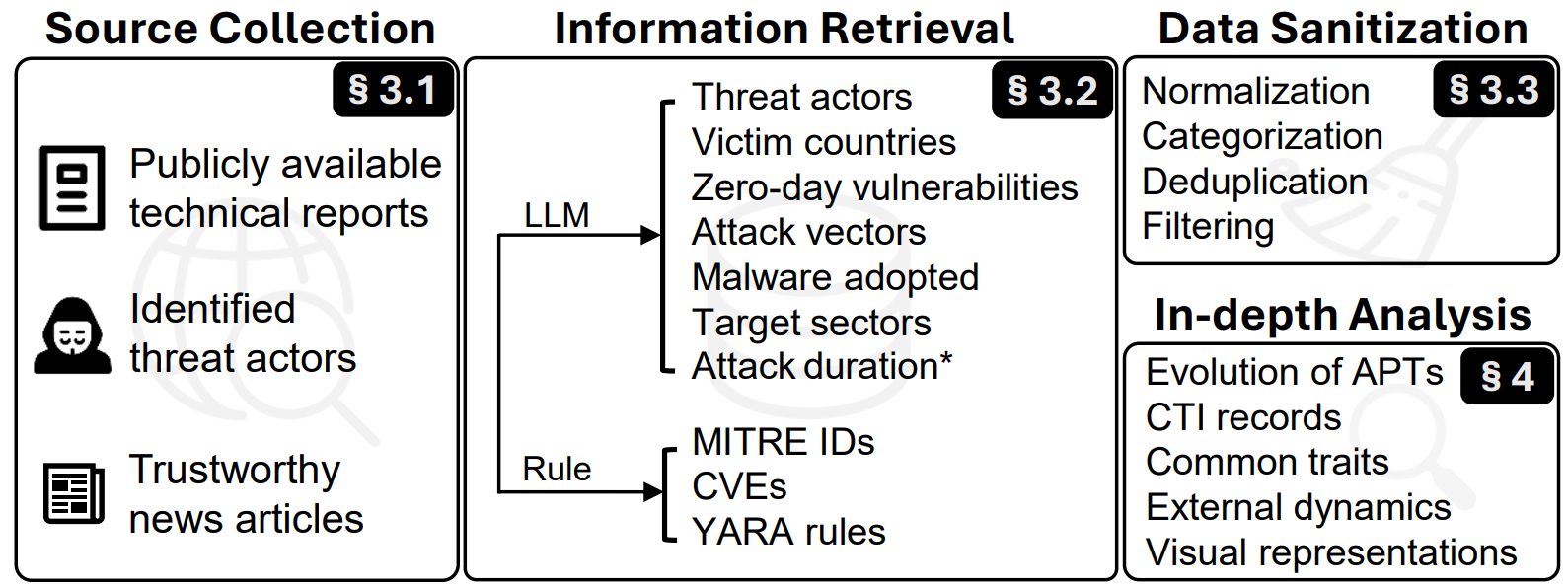
A Decade-long Landscape of Advanced Persistent Threats: Longitudinal Analysis and Global Trends
In the 32nd ACM Conference on Computer and Communications Security, 2025 (CCS '25)Distinguished Paper Award
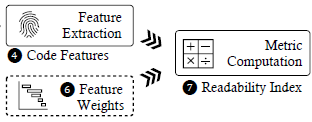
R2I: A Relative Readability Metric for Decompiled Code
In the ACM International Conference on the Foundations of Software Engineering, 2024 (FSE '24)
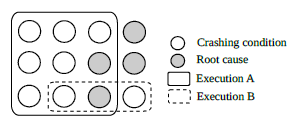
BENZENE: A Practical Root Cause Analysis System with an Under-Constrained State Mutation
In the 45th IEEE Symposium on Security and Privacy, 2024 (S&P ’24)Distinguished Paper Award
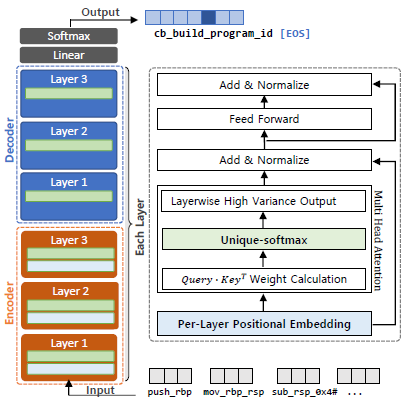
A Transformer-based Function Symbol Name Inference Model from an Assembly Language for Binary Reversing
In the 18th ACM Asia Conference on Computer and Communications Security, 2023 (ASIACCS ’23)
International Conferences and Journals
In ACM International Conference on Foundations of Software Engineering, 2026 (FSE '26)
In the Software Engineering in Practice track of the International Conference on Software Engineering, 2026 (ICSE-SEIP '26)
In Network and Distributed System Security Symposium, 2026 (NDSS ’26)
In the 41th Annual Computer Security Applications Conference, 2025 (ACSAC '25)
In the 32nd ACM Conference on Computer and Communications Security, 2025 (CCS '25)Distinguished Paper Award
In the 19th USENIX WOOT Conference on Offensive Technologies, 2025 (WOOT '25)
In the 34nd USENIX Conference on Security Symposium, 2025 (USENIX '25)
International Symposium on Foundations and Practice of Security, 2024 (FPS '24)
In the ACM International Conference on the Foundations of Software Engineering, 2024 (FSE '24)
In the 19th ACM Asia Conference on Computer and Communications Security, 2024 (ASIACCS ’24)
IEEE Access (2024)
IEEE Access (2023)
In the 45th IEEE Symposium on Security and Privacy, 2024 (S&P ’24)Distinguished Paper Award
IEEE Access (2023)
In the 45th IEEE/ACM International Conference on Software Engineering, 2023 (ICSE ’23)
In the 18th ACM Asia Conference on Computer and Communications Security, 2023 (ASIACCS ’23)
In the 38th Annual Computer Security Applications Conference (ACSAC ’22)
In the 38th Annual Computer Security Applications Conference (ACSAC ’22)
In the 24th International Conference on Advanced Communications Technology (ICACT ’22)
In the 37th Annual Computer Security Applications Conference (ACSAC ’21)
In the 37th Annual Computer Security Applications Conference (ACSAC ’21)
In the 27th ACM Conference on Computer and Communications Security (CCS ’20)
In the 39th IEEE Symposium on Security & Privacy, 2018 (S&P ’18)
In the 9th International Symposium on Engineering Secure Software and Systems, 2017 (ESSoS ’17)
In the 37th IEEE Symposium on Security and Privacy, 2016 (S&P ’16)
In the 11th ACM Asia Conference on Computer and Communications Security, 2016 (ASIACCS ’16)
In the 15th ACM Internet Measurement Conference, 2015 (IMC ’15)
Domestic Conferences and Journals
Korea Computer Congress 한국컴퓨터종합학술대회 (2026)
Korea Computer Congress 한국컴퓨터종합학술대회 (2026)
Korea Computer Congress 한국컴퓨터종합학술대회 (2026)
Review of KIISC (2026)
Journal of The Korea Institute of information Security & Cryptology (2025)
Journal of The Korea Institute of information Security & Cryptology (2025)
Journal of The Korea Institute of information Security & Cryptology (2025)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’25)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’25)
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’25)
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’25)
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’25)
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’25)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’24)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’24)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’24)
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’24) Best Paper Award
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’24)
Annual Spring Conference of KIPS (ASK’24)
Annual Spring Conference of KIPS (ASK’24)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’23)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’23)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’23)
Annual Fall Conference of KIPS (ASK ’23)
Annual Spring Conference of KIPS (ASK’23)
Annual Spring Conference of KIPS (ASK’23)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’22) Best Paper Award
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’22)
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’22)
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’22)
Workshops and Posters
Workshop on Software Understanding and Reverse Engineering (SURE'25)
Workshop on Designing Security for the Web (SecWeb ’23)
Poster in the 22nd World Conference on Information Security Applications (WISA ’21)
In the 12th European Workshop on Systems Security, 2019 (EuroSec’19)
In the 6th USENIX Workshop on Free and Open Communications on the Internet, 2016 (FOCI ’16)