
Publications
Highlighted Projects
See Full list (Google Scholar)
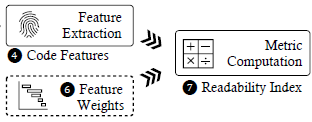
Decompilation is a process of converting a low-level machine code snippet back into a high-level programming language such as C. It serves as a basis to aid reverse engineers in comprehending the contextual semantics of the code. In this respect, commercial decompilers like Hex-Rays have made significant strides in improving the readability of decompiled code over time. While previous work has proposed the metrics for assessing the readability of source code, including identifiers, variable names, function names, and comments, those metrics are unsuitable for measuring the readability of decompiled code primarily due to i) the lack of rich semantic information in the source and ii) the presence of erroneous syntax or inappropriate expressions. In response, to the best of our knowledge, this work first introduces R2I, the Relative Readability Index, a specialized metric tailored to evaluate decompiled code in a relative context quantitatively. In essence, R2I can be computed by i) taking code snippets across different decompilers as input and ii) extracting pre-defined features from an abstract syntax tree. For the robustness of R2I, we thoroughly investigate the enhancement efforts made by existing decompilers and academic research to promote code readability, identifying 31 features to yield a reliable index collectively. Besides, we conducted a user survey to capture subjective factors such as one’s coding styles and preferences. Our empirical experiments demonstrate that R2I is a versatile metric capable of representing the relative quality of decompiled code (e.g., obfuscation, decompiler updates) and being well aligned with human perception in our survey.
Haeun Eom, Dohee Kim, Sori Lim, Hyungjoon Koo, and Sungjae Hwang
In the ACM International Conference on the Foundations of Software Engineering (FSE 2024)
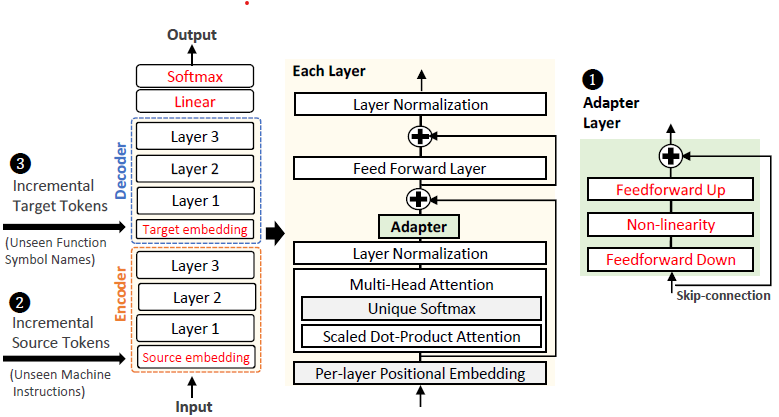
Binary reverse engineering is crucial to gain insights into the inner workings of a stripped binary. Yet, it is challenging to read the original semantics from a binary code snippet because of the unavailability of high-level information in the source, such as function names, variable names, and types. Recent advancements in deep learning show the possibility of recovering such vanished information with a well-trained model from a pre-defined dataset. Albeit a static model’s notable performance, it can hardly cope with ever-increasing data stream (e.g., compiled binaries) by nature. The two viable approaches for ceaseless learning are retraining the whole dataset from scratch and fine-tuning a pre-trained model; however, retraining suffers from large computational overheads and fine-tuning from performance degradation (i.e., catastrophic forgetting). Lately, continual learning (CL) tackles the problem of handling incremental data in security domains (e.g., network intrusion detection, malware detection) using reasonable resources while maintaining performance in practice. In this paper, we focus on how CL assists the improvement of a generative model that predicts a function symbol name from a series of machine instructions. To this end, we introduce BinAdapter, a system that can infer function names from an incremental dataset without performance degradation from an original dataset by leveraging CL techniques. Our major finding shows that incremental tokens in the source (i.e., machine instructions) or the target (i.e., function names) largely affect the overall performance of a CL-enabled model. Accordingly, BinAdapter adopts three built-in approaches: i) inserting adapters in case of no incremental tokens in both the source and target, ii) harnessing multilingual neural machine translation (M-NMT) and fine-tuning the source embeddings with i) in case of incremental tokens in the source, and iii) fine-tuning target embeddings with ii) in case of incremental tokens in both. To demonstrate the effectiveness of BinAdapter, we evaluate the above three scenarios using incremental datasets with or without a set of new tokens (e.g., unseen machine instructions or function names), spanning across different architectures and optimization levels. Our empirical results show that BinAdapter outperforms the state-of-the-art CL techniques for an F1 of up to 24.3% or a Rouge-l of 21.5% in performance.
Nozima Murodova and Hyungjoon Koo
In the 19th ACM Asia Conference on Computer and Communications Security, 2024 (ASIACCS ’24)
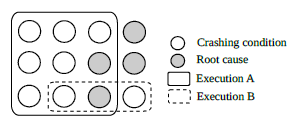
Fuzzing has demonstrated great success in bug discovery and plays a crucial role in software testing today. Despite the increasing popularity of fuzzing, automated root cause analysis (RCA) has drawn less attention. One of the recent advances in RCA is crash-based statistical debugging, which leverages the behavioral differences in program execution between crash-triggered and non-crashing inputs. Hence, obtaining non-crashing behaviors close to the original crash is crucial but challenging with previous approaches (e.g., fuzzing). In this paper, we present BENZENE, a practical end-to-end RCA system that facilitates a fully automated crash diagnosis. To this end, we introduce a novel technique, called under-constrained state mutation, that generates both crashing and non-crashing behaviors for effective and efficient RCA. We design and implement the BENZENE prototype, and evaluate it with 60 vulnerabilities in the wild. Our empirical results demonstrate that BENZENE not only surpasses in performance (i.e., root cause ranking), but also achieves superior results in both speed (4.6 times faster) and memory footprint (31.4 times less) on average than prior approaches.
Younggi Park, Hwiwon Lee, Jinho Jung, Hyungjoon Koo, and Huy Kang Kim
In the 45th IEEE Symposium on Security and Privacy, 2024 (S&P ’24)
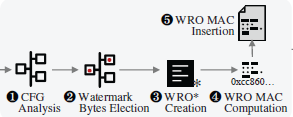
A smart contract is a self-executing program on a blockchain to ensure an immutable and transparent agreement without the involvement of intermediaries. Despite its growing popularity for many blockchain platforms like Ethereum, no technical means is available even when a smart contract requires to be protected from being copied. One of promising directions to claim a software ownership is software watermarking. However, applying existing software watermarking techniques is challenging because of the unique properties of a smart contract, such as a code size constraint, non-free execution cost, and no support for dynamic allocation under a virtual machine environment. This paper introduces a novel software watermarking scheme, dubbed SMARTMARK, aiming to protect the ownership of a smart contract against a pirate activity. SMARTMARK builds the control flow graph of a target contract runtime bytecode, and locates a collection of bytes that are randomly elected for representing a watermark. We implement a full-fledged prototype for Ethereum, applying SMARTMARK to 27,824 unique smart contract bytecodes. Our empirical results demonstrate that SMARTMARK can effectively embed a watermark into a smart contract and verify its presence, meeting the requirements of credibility and imperceptibility while incurring an acceptable performance degradation. Besides, our security analysis shows that SMARTMARK is resilient against viable watermarking corruption attacks; e.g., a large number of dummy opcodes are needed to disable a watermark effectively, resulting in producing an illegitimate smart contract clone that is not economical.
Taeyoung Kim, Yunhee Jang, Chanjong Lee, Hyungjoon Koo, and Hyoungshick Kim
In the 45th IEEE/ACM International Conference on Software Engineering, 2023 (ICSE ’23)
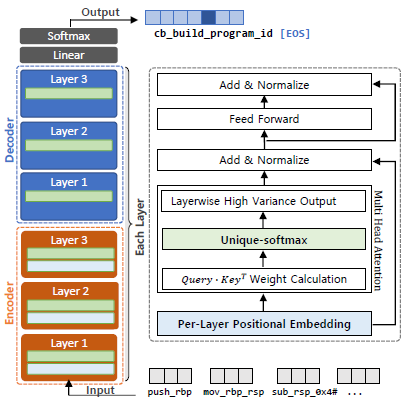
Reverse engineering of a stripped binary has a wide range of applications, yet it is challenging mainly due to the lack of contextually useful information within. Once debugging symbols (e.g., variablenames, types, function names) are discarded, recovering such informationis not technically viable with traditional approacheslike static or dynamic binary analysis. We focus on a functionsymbol name recovery, which allows a reverse engineer to gaina quick overview of an unseen binary. The key insight is that awell-developed program labels a meaningful function name thatdescribes its underlying semantics well. In this paper, we presentAsmDepictor, the Transformer-based framework that generates afunction symbol name from a set of assembly codes (i.e., machine instructions),which consists of three major components: binary coderefinement, model training, and inference. To this end, we conductsystematic experiments on the effectiveness of code refinement thatcan enhance an overall performance. We introduce the per-layerpositional embedding and Unique-softmax for AsmDepictor sothat both can aid to capture a better relationship between tokens.Lastly, we devise a novel evaluation metric tailored for a short descriptionlength, the Jaccard* score. Our empirical evaluation showsthat the performance of AsmDepictor by far surpasses that of thestate-of-the-art models up to around 400%. The best AsmDepictormodel achieves an F1 of 71.5 and Jaccard* of 75.4.
Hyunjin Kim, Jinyeong Bak, Kyunghyun Cho, and Hyungjoon Koo
In the 18th ACM Asia Conference on Computer and Communications Security, 2023 (ASIACCS ’23)
Binary code similarity detection serves as a basis for a wide spectrum of applications, including software plagiarism, malware classification, and known vulnerability discovery. However, the inference of contextual meanings of a binary is challenging due to the absence of semantic information available in source codes. Recent advances leverage the benefits of a deep learning architecture into a better understanding of underlying code semantics and the advantages of the Siamese architecture into better code similarity detection. In this paper, we propose BinShot, a BERT-based similarity learning architecture that is highly transferable for effective binary code similarity detection. We tackle the problem of detecting code similarity with one-shot learning (a special case of few-shot learning). To this end, we adopt a weighted distance vector with a binary cross entropy as a loss function on top of BERT. With the prototype implementation of BinShot, our experimental results demonstrate the effectiveness, transferability, and practicality of BinShot, which is robust to detecting the similarity of previously unseen functions.We show that BinShot outperforms the previous state-of-the-art approaches for binary code similarity detection.
Sunwoo Ahn, Seonggwan Ahn, Hyungjoon Koo, and Yunheung Paek
In the 38th Annual Computer Security Applications Conference (ACSAC ’22)
Publications: International Conferences and Journals
A Decade-long Landscape of Advanced Persistent Threats: Longitudinal Analysis and Global Trends (To appear)
Shakhzod Yuldoshkhujaev, Mijin Jeon, Doowon Kim, Nick Nikiforakis, and Hyungjoon Koo
In the 32nd ACM Conference on Computer and Communications Security (CCS’25)
BOOTKITTY: A Stealthy Bootkit-Rootkit Against Modern Operating Systems (To appear)
Junho Lee, Jihoon Kwon, HyunA Seo, Myeongyeol Lee, Hyungyu Seo, Jinho Jung, and Hyungjoon Koo
In the 19th USENIX WOOT Conference on Offensive Technologies (WOOT’25)
Evaluating the Effectiveness and Robustness of Visual Similarity-based Phishing Detection Models (To appear)
Fujiao Ji, Kiho Lee, Hyungjoon Koo, Wenhao You, Euijin Choo, Hyoungshick Kim, and Doowon Kim
In the 34nd USENIX Conference on Security Symposium (USENIX’25)
An Empirical Study of Black-box based Membership Inference Attacks on a Real-World Dataset
Yujeong Kwon, Simon S. Woo, and Hyungjoon Koo
International Symposium on Foundations and Practice of Security (FPS 2024)
R2I: A Relative Readability Metric for Decompiled Code
Haeun Eom, Dohee Kim, Sori Lim, Hyungjoon Koo, and Sungjae Hwang
In the ACM International Conference on the Foundations of Software Engineering (FSE 2024)
BinAdapter: Leveraging Continual Learning for Inferring Function Symbol Names in a Binary
Nozima Murodova and Hyungjoon Koo
In the 19th ACM Asia Conference on Computer and Communications Security, 2024 (ASIACCS ’24)
ToolPhet: Inference of Compiler Provenance from Stripped Binaries with Emerging Compilation Toolchains
Hohyeon Jang, Nozima Murodova, and Hyungjoon Koo
IEEE Access (2024)
Demystifying the Regional Phishing Landscape in South Korea
Hyunjun Park, Kyungchan Lim, Doowon Kim, Donghyun Yu, and Hyungjoon Koo
IEEE Access (2023)
BENZENE: A Practical Root Cause Analysis System with an Under-Constrained State Mutation
Younggi Park, Hwiwon Lee, Jinho Jung, Hyungjoon Koo, and Huy Kang Kim
In the 45th IEEE Symposium on Security and Privacy, 2024 (S&P ’24)
Distinguished Paper Award*
Binary Code Representation with Well-balanced Instruction Normalization
Hyungjoon Koo, Soyeon Park, Daejin Choi, and Taesoo Kim
IEEE Access (2023)
SmartMark: Software Watermarking Scheme for Smart Contracts
Taeyoung Kim, Yunhee Jang, Chanjong Lee, Hyungjoon Koo, and Hyoungshick Kim
In the 45th IEEE/ACM International Conference on Software Engineering, 2023 (ICSE ’23)
A Transformer-based Function Symbol Name Inference Model from an Assembly Language for Binary Reversing
Hyunjin Kim, Jinyeong Bak, Kyunghyun Cho, and Hyungjoon Koo
In the 18th ACM Asia Conference on Computer and Communications Security, 2023 (ASIACCS ’23)
Practical Binary Code Similarity Detection with BERT-based Transferable Similarity Learning
Sunwoo Ahn, Seonggwan Ahn, Hyungjoon Koo, and Yunheung Paek
In the 38th Annual Computer Security Applications Conference (ACSAC ’22)
DeView: Confining Progressive Web Applications by Debloating Web APIs
ChangSeok Oh, Sangho Lee, Chenxiong Qian, Hyungjoon Koo, and Wenke Lee
In the 38th Annual Computer Security Applications Conference (ACSAC ’22)
IoTivity Packet Parser for Encrypted Messages in Internet of Things
Hyeonah Jung, Hyungjoon Koo, and Jaehoon (Paul) Jeong
In the 24th International Conference on Advanced Communications Technology (ICACT ’22)
Software Watermarking via a Binary Function Relocation
Honggoo Kang, Yonghwi Kwon, Sangjin Lee, and Hyungjoon Koo
In the 37th Annual Computer Security Applications Conference (ACSAC ’21)
A Look Back on a Function Identification Problem
Hyungjoon Koo, Soyeon Park, and Taesoo Kim
In the 37th Annual Computer Security Applications Conference (ACSAC ’21)
Slimium: Debloating the Chromium Browser with Feature Subsetting
Chenxiong Qian, Hyungjoon Koo, Changseok Oh, Taesoo Kim, and Wenke Lee
In the 27th ACM Conference on Computer and Communications Security (CCS ’20)
Compiler-assisted Code Randomization
Hyungjoon Koo, Yaohui Chen, Long Lu, Vasileios P. Kemerlis, and Michalis Polychronakis
In the 39th IEEE Symposium on Security & Privacy, 2018 (S&P ’18)
Defeating Zombie Gadgets by Re-randomizing Code Upon Disclosure
Micah Morton, Hyungjoon Koo, Forrest Li, Kevin Z. Snow, Michalis Polychronakis, and Fabian Monrose
In the 9th International Symposium on Engineering Secure Software and Systems, 2017 (ESSoS ’17)
Return to the Zombie Gadgets: Undermining Destructive Code Reads via Code-Inference Attacks
Kevin Z. Snow, Roman Rogowski, Jan Werner, Hyungjoon Koo, Fabian Monrose and Michalis Polychronakis
In the 37th IEEE Symposium on Security and Privacy, 2016 (S&P ’16)
Juggling the Gadgets: Binary-level Code Randomization using Instruction Displacement
Hyungjoon Koo and Michalis Polychronakis
In the 11th ACM Asia Conference on Computer and Communications Security, 2016 (ASIACCS ’16)
Identifying Traffic Differentiation in Mobile Networks
Arash Molavi Kakhki, Abbas Razaghpanah, Anke Li, Hyungjoon Koo, Rajeshkumar Golani, David Choffnes, Phillipa Gill, and Alan Mislove
In the 15th ACM Internet Measurement Conference, 2015 (IMC ’15)
Publications: Workshops and Domestic Conferences
Advanced Persistent Threats: Addressed and Open Research Questions
Shakhzod Yuldoshkhujaev and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’24)
Trends in Attacks and Defenses against Retrieval-Augmented Generation (RAG) Systems
Minseok Kim and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’24)
Trends in Deep-learning-based Models for Anomaly Detection in Log Records
Suyeon Lee and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’24)
RoBERTa-based Obfuscated Binary Code Similarity Detection
Yujeong Kwon, Jiyong Uhm, and Hyungjoon Koo
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’24)
Best Paper Award *
Dynamic Analysis of Obfuscated Code with a 64-bit SGN Packer
Jiyong Uhm, Hyongjun Jeon, and Hyungjoon Koo
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’24)
ChatPub: Retrieval Augmented Generation-based Service to Aid in Finding Relevant Policies for Korean Youth
Gangsan Kim, Jinho Park, Seongbin Yang, Changmin Jeon, and Hyungjoon Koo
Annual Spring Conference of KIPS (ASK ’24)
Baseball Simulation Game Service Based on Baseball Metrics
Chaewon Ko, Changwoo Shim, Hyunchang Shin, and Hyungjoon Koo
Annual Spring Conference of KIPS (ASK ’24)
Trends in Machine Unlearning via Continual Learning to Mitigate Privacy Risks
Yujeong Kwon and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’23)
Trends in Membership Inference Attacks and Defenses
Nozima Murodova and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’23)
Trends in Explainable Artificial Intelligence for Security
Jiyong Uhm, Hyungjoon Jeon, and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’23)
An Unreal Engine Plugin for Text-based Runtime Animation Generation with a Motion Diffusion Model
Suho Park, Jaehoon Lee, YongHyeon Jo, Haechan Je, Daniel Cha, and Hyungjoon Koo
Annual Fall Conference of KIPS (ASK ’23)
Kingomanager: A Personalized Information-providing Application with a Recommendation System for University Students
Shingyu Kang, JunWoo Kim, ChoongHyeon Park, and Hyungjoon Koo
Annual Spring Conference of KIPS (ASK ’23)
Vulnerability Analysis of CoAP Using a Coverage-based CoAP Fuzzer
Sechang Lim and Hyungjoon Koo
Annual Spring Conference of KIPS (ASK ’23)
A Recommendation System by Extracting Scholarship Information with a BERT’s Q&A Model
Byeongjun Kang, Kyujin Kim, Jinah Park, Ijun Jang, Jaehyun Joo, and Hyungjoon Koo
Annual Spring Conference of KIPS (ASK ’23)
Evaluating Password Composition Policy and Password Meters of Popular Websites
Kyungchan Lim, Joshua Hankyul Kang, Matthew Dixson, Hyungjoon Koo, and Doowon Kim
Workshop on Designing Security for the Web (SecWeb ’23)
A Study of Executable Binaries with Emerging Compilation Tools
Hohyeon Jang and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’22)
Best Paper Award *
A Study of Rarely Appeared Instructions in an Executable Binary
Nozima Murodova and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’22)
Server-client Based Reversing Tools with a Prediction Model for Function Names
Seok Kim, Hyungjoon Jeon, Hyunjin Kim and Hyungjoon Koo
Conference on Information Security and Cryptography-Winter 한국정보보호학회 동계학술대회 (CISC-W ’22)
Phishing URL Detection with Text-CNN
Sechang Lim and Hyungjoon Koo
Conference on Information Security and Cryptography-Summer 한국정보보호학회 하계학술대회 (CISC-S ’22)
Inference of Compiler Provenance from Malware
Hohyun Jang and Hyungjoon Koo
Poster in the the 22nd World Conference on Information Security Applications (WISA ’21)
Semantic-aware Binary Code Representation with BERT
Hyungjoon Koo, Soyeon Park, Daejin Choi and Taesoo Kim
ArXiv
Configuration-Driven Software Debloating
Hyungjoon Koo, Seyedhamed Ghavamnia, and Michalis Polychronakis
In the 12th European Workshop on Systems Security, 2019 (EuroSec ’19)
The Politics of Routing: Investigating the Relationship between AS Connectivity and Internet Freedom
Rachee Singh, Hyungjoon Koo, Najmehalsadat Miramirkhani, Fahimeh Mirhaj, Leman Akoglu, and Phillipa Gill
In the 6th USENIX Workshop on Free and Open Communications on the Internet, 2016 (FOCI ’16)